
AUTHORIZATION
Blog
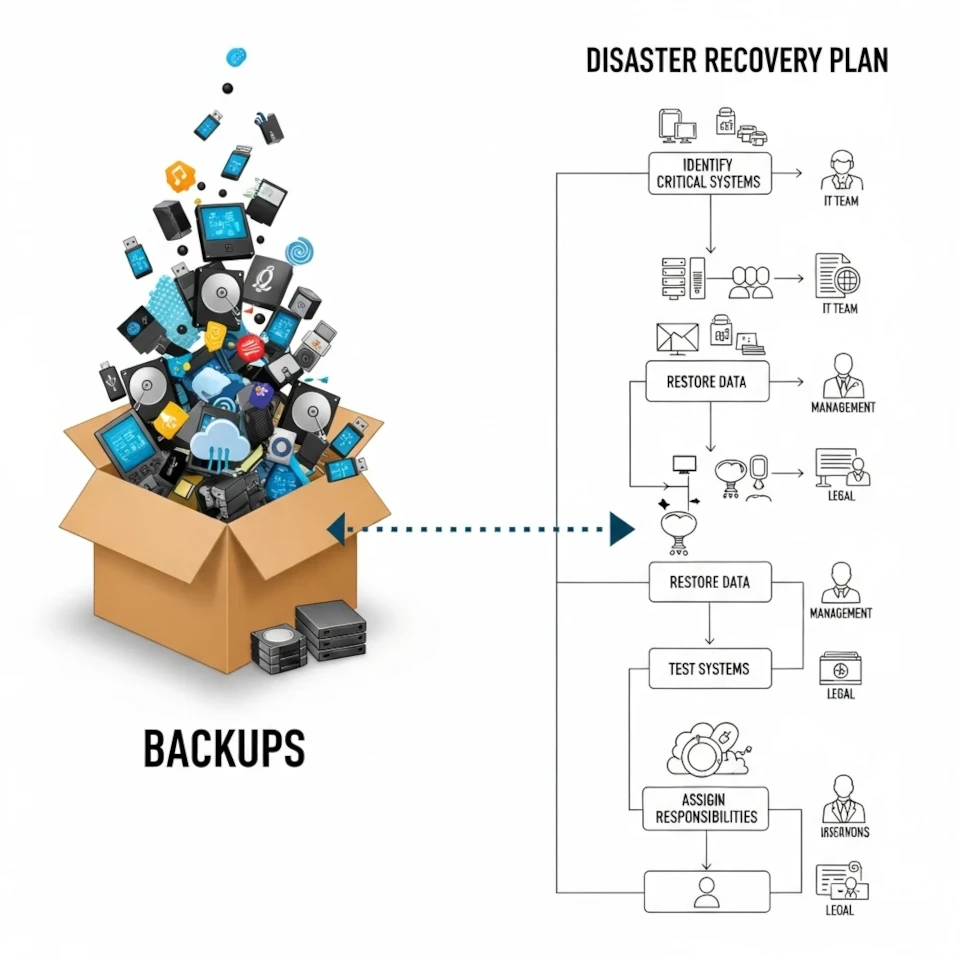
Disaster recovery plan for the company
At 10:17 the accounting system is no longer available, files won't open, and employees start writing to each other to see if the problem is just on their end. By 10:40, it becomes clear that this is not an isolated failure. It is precisely at this moment that the disaster recovery plan transforms from a theoretical document into a business survival tool.
Many managers still assume that backups automatically resolve recovery issues. They do not. A backup merely indicates that data has been stored somewhere. The disaster recovery plan specifies the order, speed, and accountability with which a company restores critical systems, processes, and access. These are two related but different issues.

What is a disaster recovery plan in practice
Simply put, a disaster recovery plan is a predefined course of action in the event of IT disruptions, cybersecurity incidents, or infrastructure failures. It describes what is restored first, from which sources, who makes decisions, and how the company's operations are maintained until full recovery.
For small and medium-sized enterprises, this plan is usually not complicated because the environment is not large. It becomes complex because systems have developed piecemeal over the years - one vendor maintains the server, another manages the email, a third has installed the business application, but no one has a complete understanding of the priorities. During an incident, such a model creates delays rather than control.
A good plan is not written solely for the IT team. It is a management tool. It helps managers understand how long downtime is acceptable, which functions should be restored in the first hours, and what level of risk the company faces if a system is down for one day, three days, or a week.
Why disaster recovery plans are not just an IT issue
If the ERP system is down, it affects not only the IT environment. The warehouse stops, invoicing is delayed, customer service works with incomplete information, and management makes decisions without up-to-date data. Therefore, recovery priorities cannot be determined solely based on technical principles - the most important server is not always the most critical business process.
This is where the most common mistake arises. The company thinks at the system level, but not at the process level. For example, a file server may seem critical, however, the sales team can temporarily work with limited access. On the other hand, downtime on the customer order platform, even for a few hours, can lead to direct revenue losses. Without a clear map between technology and business impact, recovery often occurs in the wrong order.
Thus, the disaster recovery plan does not start with a list of technologies, but with the question - what must remain functional under any circumstances for the company. The answer could be financial accounting, customer service, production management, remote access for the team, or a specific database. Only then can reasonable technical decisions be made.
What such a plan includes
A practically usable plan usually consists of several interrelated parts. The first is the inventory of critical systems and services. Not a general list, but clearly stated which platforms, servers, applications, and datasets are directly related to business continuity.
The second part is recovery priorities. It is essential to define the acceptable downtime and acceptable data loss for each system. If email functionality can be restored within a few hours, but the ordering system requires nearly continuous operation, these differences must be clearly documented. Otherwise, during an incident, everyone demands immediate restoration, which is not practical.
The third part is the distribution of responsibilities. Who activates the plan, who communicates with suppliers, who informs management, who decides on switching to the backup environment. If these issues are not resolved in advance, hours, rather than minutes, are lost during an incident.
The fourth part is technical recovery. It must include documented backup sources, the order of recovery, access keys, alternative infrastructure, the role of cloud services, and dependencies between systems. Very often, companies find that data can theoretically be restored, but there is no license, authentication service, or network configuration available, without which the restored environment is unusable.
The most common mistakes that increase incident costs
The most expensive cost is usually not the disaster itself, but poorly prepared recovery. A classic example is when backups are made but not tested. On paper, everything looks correct, but on the day of the incident, it turns out that the copy is corrupted, incomplete, or can only be restored with manual intervention that no one has thought about.
Another common mistake is the belief that cloud services automatically mean full recovery readiness. This depends on the specific solution. In some cases, the service provider ensures platform availability but does not guarantee your data's granularity, version restoration, or configuration flexibility. The cloud environment reduces some risks but does not negate the need for a plan.
The third mistake is creating a document for audit purposes rather than for real use. If the disaster recovery plan is too general, filled with outdated contact information, or written as if no one would ever open it in a stressful situation, it will not be helpful. A good plan is clear, concise where it should be brief, and sufficiently detailed where details are necessary.
How to determine the right recovery level
Not every company needs an expensive high-availability architecture. However, almost every company needs clarity about what happens when a critical system is not available. The right recovery level is always a compromise between risk, cost, and the business's tolerance for downtime.
If a company operates with relatively low transaction intensity and can safely endure one workday without a specific system, a simpler model is sufficient. If every hour directly affects revenue, customer service, or contractual obligations, a much faster recovery mechanism is needed. There is no one-size-fits-all solution. The right approach comes from business reality, not from what sounds technically impressive.
Therefore, management must ask itself uncomfortable yet necessary questions. How much does one hour of downtime cost? How much data can the company afford to lose? Are critical systems dependent on one person's knowledge? Is it clear how to respond if an incident occurs outside of working hours? These answers shape the plan's quality more than any single technology.
Disaster recovery plans must be tested, not just stored
A plan without testing is an assumption. Testing is not a formality but a way to uncover weaknesses while they are still not a business problem. Often, it is during testing that it becomes clear that the sequence of recovery is illogical, access is outdated, or a particular system takes much longer than initially anticipated.
Tests do not necessarily have to be full-scale simulations every month. Some companies are satisfied with regular recovery scenario tests, partial system tests, and management-level tabletop simulations. It is important for the plan to be alive and connected to the real environment. If the company changes its infrastructure, implements a new business application, or migrates part of its systems to the cloud, the plan must be updated immediately, not after a year.
Here, external perspectives often provide great value. Not because the internal team cannot understand their environment, but because it is difficult to notice assumptions and unseen risks in day-to-day operations. That is why companies increasingly choose to audit or review their disaster recovery plans with a partner who simultaneously understands technical infrastructure and business priorities. KSK IT works precisely at this intersection - between operational execution and management-level control.
When is the right time to create or review a plan
Typically, one does not wait until an incident occurs; however, in practice, it is often an incident that becomes the impetus. A smarter approach is to act earlier - before moving offices, before implementing a new ERP, after an acquisition, during rapid growth, or when the IT environment has become too reliant on specific individuals or historical solutions.
If a company does not have clear answers to the question of how quickly critical systems can be restored, that is already a sufficient signal for a review. The same applies to situations where backups are maintained, but no one has documented the full recovery sequence. Such a model may function until the first serious disruption. After that, it becomes costly.
A robust disaster recovery plan does not guarantee that an incident will not occur. It offers something else - predictability, accountability, and a much better opportunity to preserve business operations when conditions are unfavorable. That is why this work is worth doing before the rush, before losses, and before someone in a management meeting is forced to answer why no one really knew what to do.